

Object Detection Tutorial in TensorFlow: Real-Time Object Detection
Creating correct Machine Learning Models which can be capable of identifying and localizing more than one objects in a unmarried image remained a core project in pc vision. But, with current improvements in Deep Learning, Object Detection packages are simpler to expand than ever before. TensorFlow’s Object Detection API is an open supply framework constructed on top of TensorFlow that makes it smooth to construct, train and set up object detection models.

So guys, in this Object Detection Tutorial, I’ll be protecting the subsequent topics:
- What is Object Detection?
- Different Applications of Object Detection
- Object Detection Workflow
- What is Tensorflow?
- Object Detection with Tensorflow (Demo)
- Real-Time/Live Object Detection (Demo)

What is Object Detection?
Object Detection is the procedure of locating real-global object times like car, motorcycle, TV, flora, and humans in still snap shots or Videos. It permits for the popularity, localization, and detection of multiple objects within an picture which presents us with a far higher information of an photograph as a whole. It is generally utilized in applications which include image retrieval, safety, surveillance, and superior driver assistance systems (ADAS).
Object Detection can be carried out thru more than one approaches:
- Feature-Based Object Detection
- Viola Jones Object Detection
- SVM Classifications with HOG Features
- Deep Learning Object Detection
In this Object Detection Tutorial, we’ll attention on Deep Learning Object Detection as Tensorflow uses Deep Learning for computation.

Let’s circulate ahead with our Object Detection Tutorial and recognize it’s diverse packages inside the enterprise.
Applications Of Object Detection
 Facial Recognition:
Facial Recognition:
Face-Recognition-Object Detection Tutorial
A deep studying facial popularity machine known as the “DeepFace” has been developed through a group of researchers inside the Facebook, which identifies human faces in a digital photograph very correctly. Google uses its own facial reputation gadget in Google Photos, which robotically segregates all of the images primarily based at the person within the photo. There are diverse additives involved in Facial Recognition like the eyes, nose, mouth and the eyebrows.
People Counting:

People-Count-Object Detection Tutorial
Object detection may be extensively utilized for people counting, it's far used for reading save performance or crowd information throughout festivals. These tend to be greater difficult as people circulate out of the frame fast.
It is a very vital software, as in the course of crowd accumulating this option can be used for a couple of functions.
Industrial Quality Check:

Quality-exams-Object Detection Tutorial
Object detection is likewise utilized in industrial procedures to pick out products. Finding a selected object via visible inspection is a primary assignment this is worried in multiple commercial methods like sorting, inventory management, machining, quality control, packaging etc.
Inventory control may be very complex as items are tough to tune in real time. Automatic object counting and localization allows enhancing stock accuracy.
Self Driving Cars:

Self-Driving-Car-Object Detection Tutorial
Self-driving motors are the Future, there’s no question in that. But the working behind it's far very problematic as it combines an expansion of strategies to understand their surroundings, such as radar, laser mild, GPS, odometry, and pc imaginative and prescient.
Advanced control structures interpret sensory records to become aware of appropriate navigation paths, in addition to boundaries and as soon as the photograph sensor detects any signal of a residing being in its direction, it routinely stops. This takes place at a totally fast price and is a large step towards Driverless Cars.

Object Detection plays a completely important function in Security. Be it face ID of Apple or the retina scan utilized in all the sci-fi films.
It is likewise used by the government to get entry to the safety feed and match it with their existing database to discover any criminals or to come across the robbers’ automobile.
The packages are limitless.
Object Detection Workflow
Every Object Detection Algorithm has a unique way of running, however all of them paintings on the identical precept.
Feature Extraction: They extract features from the input photographs at hands and use those functions to determine the magnificence of the photograph. Be it through MatLab, Open CV, Viola Jones or Deep Learning.

Now that you have understood the fundamental workflow of Object Detection, permit’s flow beforehand in Object Detection Tutorial and understand what Tensorflow is and what are its additives?
What is TensorFlow?
Tensorflow is Google’s Open Source Machine Learning Framework for dataflow programming throughout a number obligations. Nodes within the graph represent mathematical operations, even as the graph edges represent the multi-dimensional records arrays (tensors) communicated among them.

Tensors are just multidimensional arrays, an extension of 2-dimensional tables to statistics with a higher size. There are many functions of Tensorflow which makes it suitable for Deep Learning. So, with out losing any time, allow’s see how we will implement Object Detection the usage of Tensorflow.
Object Detection Tutorial
Getting Prerequisites
Before working on the Demo, let’s have a have a look at the prerequisites. We might be desiring:
- Python
- TensorFlow
- Tensorboard
- Protobuf v3.4 or above
Setting up the Environment
Now to Download TensorFlow and TensorFlow GPU you can use pip or conda commands:

For all of the different libraries we are able to use pip or conda to put in them. The code is furnished underneath:
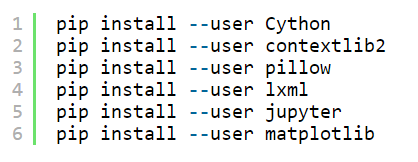
- Next, we have Protobuf: Protocol Buffers (Protobuf) are Google’s language-impartial, platform-impartial, extensible mechanism for serializing based facts, – think about it like XML, however smaller, quicker, and less complicated. You need to Download Protobuf version 3.4 or above for this demo and extract it.
- Now you need to Clone or Download TensorFlow’s Model from Github. Once downloaded and extracted rename the “models-masters” to just “fashions“.
- Now for simplicity, we are going to preserve “models” and “protobuf” below one folder “Tensorflow“.
- Next, we need to head in the Tensorflow folder and then internal studies folder and run protobuf from there the use of this command:
- 1. "path_of_protobuf's bin"./bin/protoc object_detection/protos/
- To check whether this worked or no longer, you may go to the protos folder interior models>object_detection>protos and there you may see that for each proto record there’s one python file created.
Main Code 
After the surroundings is set up, you want to go to the “object_detection” listing and then create a new python report. You can use Spyder or Jupyter to put in writing your code.
- First of all, we want to import all the libraries
import numpy as npimport osimport six.moves.urllib as urllibimport sysimport tarfileimport tensorflow as tfimport zipfilefrom collections import defaultdictfrom io import StringIOfrom matplotlib import pyplot as pltfrom PIL import Imagesys.path.append("..")from object_detection.utils import ops as utils_opsfrom utils import label_map_utilfrom utils import visualization_utils as vis_util
Next, we will down load the version which is educated at the COCO dataset.COCO stands for Common Objects in Context, this dataset contains round 330K classified pix. Now the version choice is essential as you need to make an critical tradeoff among Speed and Accuracy. Depending upon your requirement and the machine reminiscence, the ideal model should be decided on.
Inside “models>research>object_detection>g3doc>detection_model_zoo”carries all the models with one of a kind speed and accuracy(mAP).

Next, we provide the required version and the frozen inferencegraph generated with the aid of Tensorflow to use.
ODEL_NAME = 'ssd_mobilenet_v1_coco_2017_11_17'MODEL_FILE = MODEL_NAME + '.tar.gz'DOWNLOAD_BASE = '<a href="http://download.tensorflow.org/models/object_detection/">http://download.tensorflow.org/models/object_detection/</a>' PATH_TO_CKPT = MODEL_NAME + '/frozen_inference_graph.pb' PATH_TO_LABELS = os.path.join('data', 'mscoco_label_map.pbtxt') NUM_CLASSES = 90
This code will download that model from the internet and extract- the frozen inference graph of that version.
opener=urllib.request.URLopener()opener.retrieve(DOWNLOAD_BASE+MODEL_FILE, MODEL_FILE)tar_file=tarfile.open(MODEL_FILE)forfileintar_file.getmembers():file_name=os.path.basename(file.name)if'frozen_inference_graph.pb'infile_name:tar_file.extract(file, os.getcwd())detection_graph=tf.Graph()- with detection_graph.as_default():
od_graph_def=tf.GraphDef()with tf.gfile.GFile(PATH_TO_CKPT,'rb') as fid:serialized_graph=fid.read()od_graph_def.ParseFromString(serialized_graph)tf.import_graph_def(od_graph_def, name='')
- Next, we are going to load all the labels
123 label_map = label_map_util.load_labelmap(PATH_TO_LABELS)categories = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=NUM_CLASSES, use_display_name=True)category_index = label_map_util.create_category_index(categories)
- Now we will convert the images data into a numPy array for processing.
1234 def load_image_into_numpy_array(image): (im_width, im_height) = image.size return np.array(image.getdata()).reshape( (im_height, im_width, 3)).astype(np.uint8)
- The path to the images for the testing purpose is defined here. Here we have a naming convention “image[i]” for i in (1 to n+1), n being the number of images provided.
12 PATH_TO_TEST_IMAGES_DIR = 'test_images'TEST_IMAGE_PATHS = [ os.path.join(PATH_TO_TEST_IMAGES_DIR, 'image{}.jpg'.format(i)) for i in range(1, 8) ]
- This code runs the inference for a single image, where it detects the objects, make boxes and provide the class and the class score of that particular object.
123456789101112131415161718192021222324252627282930313233343536373839404142434445 def run_inference_for_single_image(image, graph): with graph.as_default(): with tf.Session() as sess: # Get handles to input and output tensors ops = tf.get_default_graph().get_operations() all_tensor_names = {output.name for op in ops for output in op.outputs} tensor_dict = {} for key in [ 'num_detections', 'detection_boxes', 'detection_scores', 'detection_classes', 'detection_masks' ]: tensor_name = key + ':0' if tensor_name in all_tensor_names: tensor_dict[key] = tf.get_default_graph().get_tensor_by_name( tensor_name) if 'detection_masks' in tensor_dict: # The following processing is only for single image detection_boxes = tf.squeeze(tensor_dict['detection_boxes'], [0]) detection_masks = tf.squeeze(tensor_dict['detection_masks'], [0]) # Reframe is required to translate mask from box coordinates to image coordinates and fit the image size. real_num_detection = tf.cast(tensor_dict['num_detections'][0], tf.int32) detection_boxes = tf.slice(detection_boxes, [0, 0], [real_num_detection, -1]) detection_masks = tf.slice(detection_masks, [0, 0, 0], [real_num_detection, -1, -1]) detection_masks_reframed = utils_ops.reframe_box_masks_to_image_masks( detection_masks, detection_boxes, image.shape[0], image.shape[1]) detection_masks_reframed = tf.cast( tf.greater(detection_masks_reframed, 0.5), tf.uint8) # Follow the convention by adding back the batch dimension tensor_dict['detection_masks'] = tf.expand_dims( detection_masks_reframed, 0) image_tensor = tf.get_default_graph().get_tensor_by_name('image_tensor:0') # Run inference output_dict = sess.run(tensor_dict, feed_dict={image_tensor: np.expand_dims(image, 0)}) # all outputs are float32 numpy arrays, so convert types as appropriate output_dict['num_detections'] = int(output_dict['num_detections'][0]) output_dict['detection_classes'] = output_dict[ 'detection_classes'][0].astype(np.uint8) output_dict['detection_boxes'] = output_dict['detection_boxes'][0] output_dict['detection_scores'] = output_dict['detection_scores'][0] if 'detection_masks' in output_dict: output_dict['detection_masks'] = output_dict['detection_masks'][0]return output_dict
- Our Final loop, which will call all the functions defined above and will run the inference on all the input images one by one, which will provide us the output of images in which objects are detected with labels and the percentage/score of that object being similar to the training data.
123456789101112131415161718192021 for image_path in TEST_IMAGE_PATHS: image = Image.open(image_path) # the array based representation of the image will be used later in order to prepare the # result image with boxes and labels on it. image_np = load_image_into_numpy_array(image) # Expand dimensions since the model expects images to have shape: [1, None, None, 3] image_np_expanded = np.expand_dims(image_np, axis=0) # Actual detection. output_dict = run_inference_for_single_image(image_np, detection_graph) # Visualization of the results of a detection. vis_util.visualize_boxes_and_labels_on_image_array( image_np, output_dict['detection_boxes'], output_dict['detection_classes'], output_dict['detection_scores'], category_index, instance_masks=output_dict.get('detection_masks'), use_normalized_coordinates=True, line_thickness=8)plt.figure(figsize=IMAGE_SIZE)plt.imshow(image_np)

Now, let’s flow ahead in our Object Detection Tutorial and see how we can detect gadgets in Live Video Feed.
Live Object Detection Using Tensorflow
For this Demo, we can use the identical code, but we’ll do some tweakings. Here we are going to use OpenCV and the digicam Module to apply the live feed of the webcam to discover items.
Add the OpenCV library and the digicam being used to seize pix. Just add the following strains to the import library section.
- import cv2
cap = cv2.VideoCapture(0)
- Next, we don’t need to load the images from the directory and
- convert it to numPy array as OpenCV will take care of that fo us
Remove This
12345 for image_path in TEST_IMAGE_PATHS:image = Image.open(image_path)# the array based representation of the image will be used later in order to prepare the# result image with boxes and labels on it.image_np = load_image_into_numpy_array(image)
With
12 while True:ret, image_np = cap.read()
We will now not use matplotlib for final image show as an alternative, we will use OpenCV for that as properly. Now, for that,
Remove This
12 plt.figure(figsize=IMAGE_SIZE)plt.imshow(image_np)
With
1234 cv2.imshow('object detection', cv2.resize(image_np, (800,600)))if cv2.waitKey(25) & 0xFF == ord('q'): cv2.destroyAllWindows() break
This code will use OpenCV so as to, in flip, use the digitalcamera item initialized earlier to open a brand new window name“Object_Detection” of the size “800×600”. It will look forward to 25 milliseconds for the camera to expose images in any other case, it'll
near the window.
Final Code with all the changes:
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071727374757677787980818283848586 import numpy as npimport osimport six.moves.urllib as urllibimport sysimport tarfileimport tensorflow as tfimport zipfile from collections import defaultdictfrom io import StringIOfrom matplotlib import pyplot as pltfrom PIL import Image import cv2cap = cv2.VideoCapture(0) sys.path.append("..") from utils import label_map_util from utils import visualization_utils as vis_util MODEL_NAME = 'ssd_mobilenet_v1_coco_11_06_2017'MODEL_FILE = MODEL_NAME + '.tar.gz'DOWNLOAD_BASE = '<a href="http://download.tensorflow.org/models/object_detection/">http://download.tensorflow.org/models/object_detection/</a>' # Path to frozen detection graph. This is the actual model that is used for the object detection.PATH_TO_CKPT = MODEL_NAME + '/frozen_inference_graph.pb' # List of the strings that is used to add correct label for each box.PATH_TO_LABELS = os.path.join('data', 'mscoco_label_map.pbtxt') NUM_CLASSES = 90 opener = urllib.request.URLopener()opener.retrieve(DOWNLOAD_BASE + MODEL_FILE, MODEL_FILE)tar_file = tarfile.open(MODEL_FILE)for file in tar_file.getmembers(): file_name = os.path.basename(file.name) if 'frozen_inference_graph.pb' in file_name: tar_file.extract(file, os.getcwd()) detection_graph = tf.Graph()with detection_graph.as_default(): od_graph_def = tf.GraphDef() with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid: serialized_graph = fid.read() od_graph_def.ParseFromString(serialized_graph) tf.import_graph_def(od_graph_def, name='') label_map = label_map_util.load_labelmap(PATH_TO_LABELS)categories = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=NUM_CLASSES, use_display_name=True)category_index = label_map_util.create_category_index(categories) with detection_graph.as_default(): with tf.Session(graph=detection_graph) as sess: while True: ret, image_np = cap.read() # Expand dimensions since the model expects images to have shape: [1, None, None, 3] image_np_expanded = np.expand_dims(image_np, axis=0) image_tensor = detection_graph.get_tensor_by_name('image_tensor:0') # Each box represents a part of the image where a particular object was detected. boxes = detection_graph.get_tensor_by_name('detection_boxes:0') # Each score represent how level of confidence for each of the objects. # Score is shown on the result image, together with the class label. scores = detection_graph.get_tensor_by_name('detection_scores:0') classes = detection_graph.get_tensor_by_name('detection_classes:0') num_detections = detection_graph.get_tensor_by_name('num_detections:0') # Actual detection. (boxes, scores, classes, num_detections) = sess.run( [boxes, scores, classes, num_detections], feed_dict={image_tensor: image_np_expanded}) # Visualization of the results of a detection. vis_util.visualize_boxes_and_labels_on_image_array( image_np, np.squeeze(boxes), np.squeeze(classes).astype(np.int32), np.squeeze(scores), category_index, use_normalized_coordinates=True, line_thickness=8) cv2.imshow('object detection', cv2.resize(image_np, (800,600))) if cv2.waitKey(25) 0xFF == ord('q'): cv2.destroyAllWindows() break

Now with this, we come to an quit to this Object Detection Tutorial. I Hope you me enjoyed this text and understood the strength of Tensorflow,and the way smooth it is to locate gadgets in pics and video feed. So, if you have read this, you're no longer a newbie to Object Detection and TensorFlow. Try out those examples and allow me recognize if there are any demanding situations you are going through at the same time as deploying the code.
Golden card:
- 1:1 Paid Session
- 1:1 Sessions for different soft skill courses
- Project Development
Related Articles :




{kind=link}
0 Comments